O2A: One-shot Observational Learning with Action Vectors
Journal
L. Pauly, W. C. Agboh, D. C. Hogg, and R. Fuentes, "O2A: One-Shot Observational
Learning with Action Vectors", at Frontiers in Robotics and AI, Vol.8, pp.239, 2021.
[paper]
[slides]
[bibtex]
Workshops
"One-shot observation learning", at IROS Workshop: Examining Sensing Modalities
for Robust and Dexterous manipulation, IROS, 2018.
"One-shot observation learning using visual activity features", at 3rd UK robotics
manipulation workshop, 2019.
"One-shot observational learning", at AI @ Leeds workshop, 2019.
I. Overview:
We present O2A, a novel method for learning to perform robotic manipulation tasks from a single (one-shot) third-person demonstration. To our knowledge, it is the first time this has been done for a single demonstration. The key novelty lies in pre-training a feature extractor for creating a perceptual representation for actions called 'action vectors'. We pre-train a 3D-CNN action vector extractor as an action classifier on a generic action dataset. The action vectors from the observed third-person demonstration and trial robot executions are used to generate rewards for reinforcement learning of the demonstrated task. We report on experiment in simulation and on a real robot, with changes in viewpoint of observation, properties of the objects involved, scene background and morphology of the manipulator between the demonstration and the learning domains. O2A outperforms the baseline approaches under different domain shifts and has comparable performance with Oracle.
II. Dataset
The Leeds Manipulation Dataset (LMD) is available from: here.
III. Results:
We present the performance of O2A in the robotic experiments. Video clips of the demonstration and execution of correspoding learned optimal policy (for simulation experiment) or optimal sequence obtained (for real robot experiment) are given below. Results are shown for action vectors extracted from pool5 layer of NN:UCF101 model.
Reaching a target (Simulation)
| Demonstration | Optimal policy execution - V1 |
Optimal policy execution - Obj1 |
Optimal policy execution - BG |
|||
|---|---|---|---|---|---|---|
 |

|
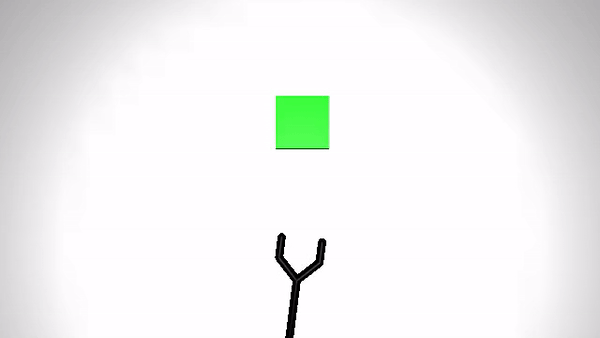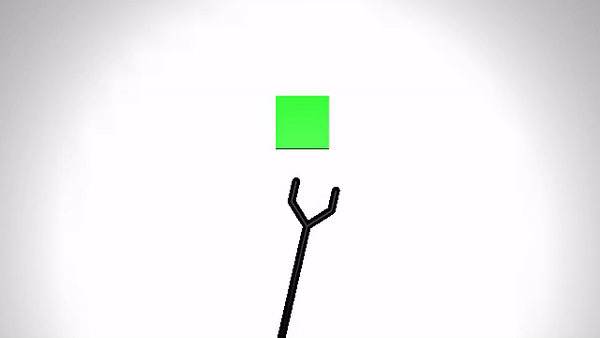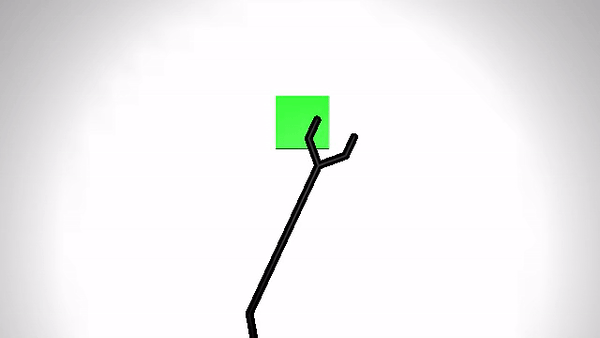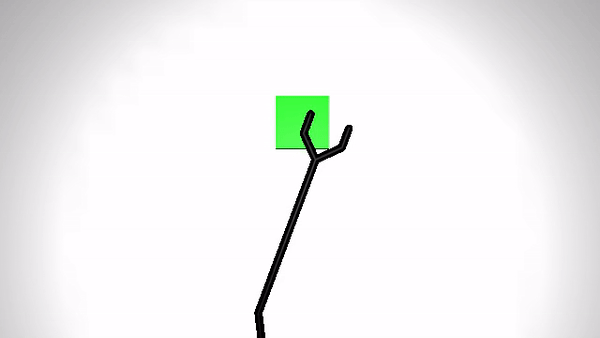
|
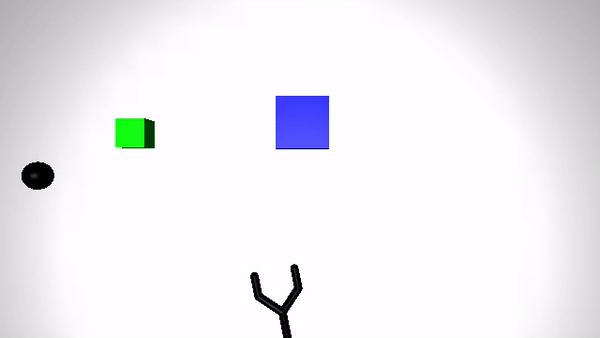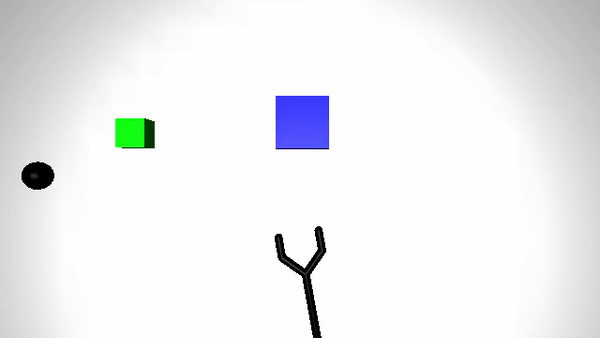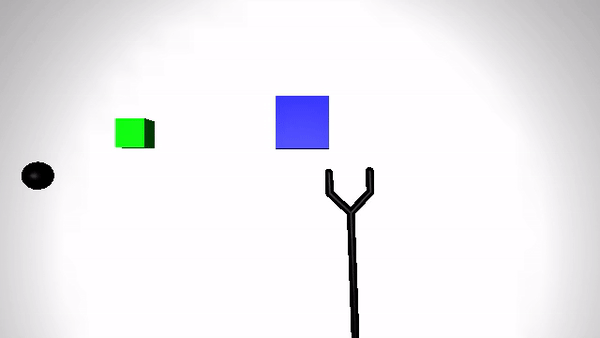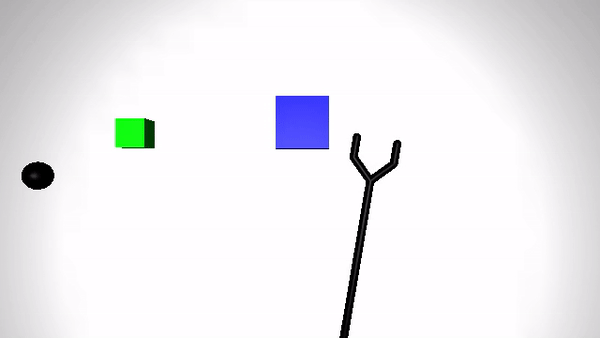
|
|||
| Demonstration | Optimal policy execution- V2 |
Optimal policy execution - Obj2 |
Demonstration | Optimal policy execution- M |
||
 |

|
|
 |
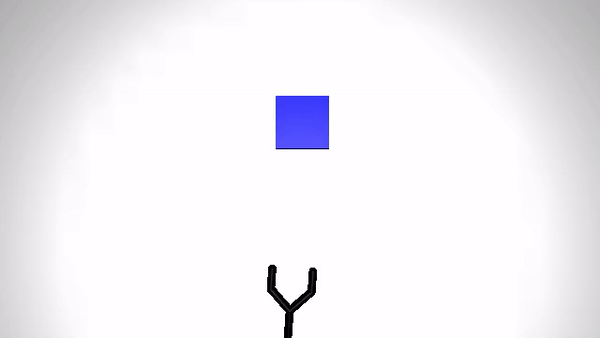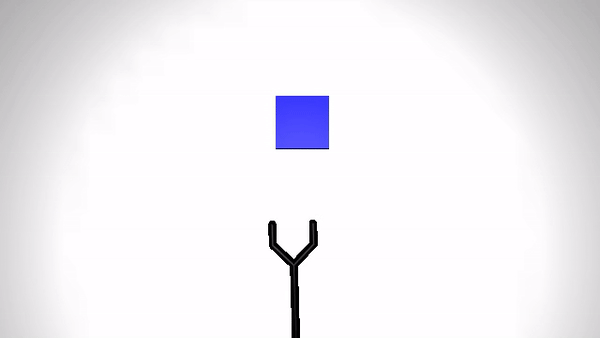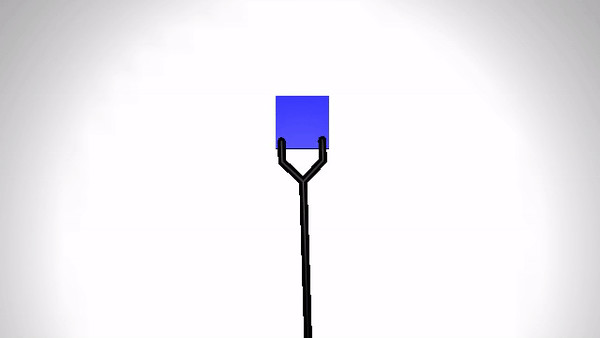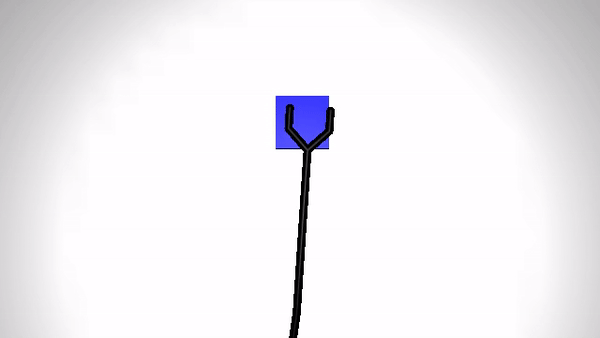
|
Pushing an object (Simulation)
| Demonstration | Optimal policy execution - V1 |
Optimal policy execution - Obj1 |
Optimal policy execution - BG |
|||
|---|---|---|---|---|---|---|
 |

|

|
|
|||
| Demonstration | Optimal policy execution- V2 |
Optimal policy execution - Obj2 |
Demonstration | Optimal policy execution- M |
||
 |

|

|
huma.gif) |

|
Pushing an object (real robot)
| Demonstration | Optimal sequence execution - V1 |
Optimal sequence execution - Obj1 |
Optimal sequence execution - BG |
|||
|---|---|---|---|---|---|---|
 |

|

|

|
|||
| Demonstration | Optimal sequence execution- V2 |
Optimal sequence execution - Obj2 |
Demonstration | Optimal sequence execution- M |
||
 |

|

|
 |

|
Hammering (real robot)
| Demonstration | Optimal sequence execution - V1 |
Optimal sequence execution - Obj1 |
Optimal sequence execution - Obj2 |
Optimal sequence execution- M |
Optimal sequence execution - BG |
|
|---|---|---|---|---|---|---|
 |

|

|

|

|

|
|
| Demonstration | Optimal sequence execution- V2 |
|||||
 |

|
Sweeping (real robot)
| Demonstration | Optimal sequence execution - V1 |
Optimal sequence execution - BG |
Demonstration | Optimal sequence execution- V2 |
||||
|---|---|---|---|---|---|---|---|---|
 |

|

|
 |

|
Striking (real robot)
| Demonstration | Optimal sequence execution - V1 |
Optimal sequence execution - BG |
Demonstration | Optimal sequence execution- V2 |
||||
|---|---|---|---|---|---|---|---|---|
 |

|

|
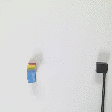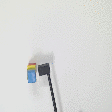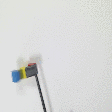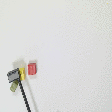
|

|